
concurrent.futures != asyncioWhile they both deal with asynchronous programming, they employ different approaches and are suited to different types of tasks.
To be clear, they’re both limited by Global Interpreter Lock (GIL) and are both single process, multi-thread. They are both forms of concurrency but not parallelism.
I used to be using
concurrent.futuresuntil I learntasyncio.
Using concurrent.futures#
There are 2 ways to use concurrent.futures:
ThreadPoolExecutor- Best used for I/O-bound tasks (such as file reading and network request).ProcessPoolExecutor- Suitable for CPU-intensive tasks (such as math computations).
Let’s see 2 examples here. Here’s the sample on ThreadPoolExecutor():
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
from rich import print as rprint
from timeit import default_timer as timer
import concurrent.futures
import requests
def timeit(func):
def timed(*args, **kwargs):
stime = timer()
result = func(*args, **kwargs)
etime = timer()
rprint(f'\n [*] {func.__name__}(): completed within [{etime-stime:.4f} sec].\n ')
return result
return timed
def fetch_url(url):
resp = requests.get(url)
return url, resp.status_code, resp.elapsed.total_seconds()
@timeit
def singlethread():
for url in urls:
_, status_code, elapsed = fetch_url(url)
rprint(f"URL: {url} [ {status_code} / {elapsed:.4f} ]")
@timeit
def multithread():
with concurrent.futures.ThreadPoolExecutor() as executor:
futures = [executor.submit(fetch_url, url) for url in urls]
for future in concurrent.futures.as_completed(futures):
url, status_code, elapsed = future.result()
rprint(f"URL: {url} [ {status_code} / {elapsed:.4f} ]")
if __name__ == "__main__":
urls = [
"https://www.bing.com",
"https://www.duckduckgo.com",
"https://www.google.com",
"https://www.yahoo.com"
]
print(f'')
singlethread()
multithread()
Here is the output:
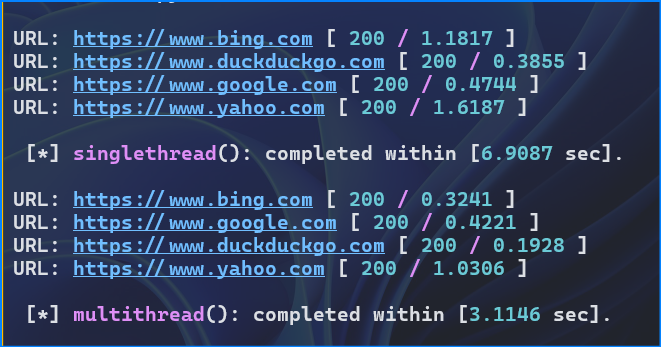
Here’s the sample on PorcessPoolExecutor():
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
from rich import print as rprint
from timeit import default_timer as timer
import concurrent.futures
import time
def timeit(func):
def timed(*args, **kwargs):
stime = timer()
result = func(*args, **kwargs)
etime = timer()
rprint(f'\n [*] {func.__name__}(): completed within [{etime-stime:.4f} sec].\n ')
return result
return timed
def my_function(x):
time.sleep(2)
return x, x * x
@timeit
def without_executor(numbers):
results = []
for num in numbers:
start_time = time.time()
x, result = my_function(num)
end_time = time.time()
print(f"Without_executor: {x} squared = {result} [ {end_time - start_time:.2f} sec ]")
results.append(result)
return results
@timeit
def with_executor(numbers):
with concurrent.futures.ProcessPoolExecutor() as executor:
results = [executor.submit(my_function, num) for num in numbers]
for f in concurrent.futures.as_completed(results):
x, result = f.result()
print(f"With_executor: {x} squared = {result} ")
return results
if __name__ == "__main__":
numbers = [2, 3, 4]
print(f'')
without_executor(numbers)
with_executor(numbers)
Here is the output:
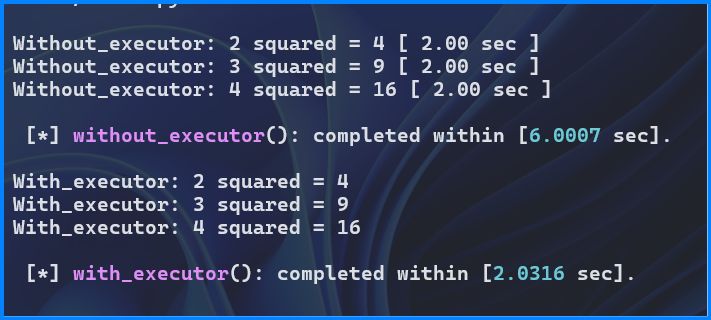
Key Differences#
| Feature | concurrent.futures | asyncio |
|---|---|---|
| Underlying mechanism | Threads/Processes | Event-loop |
| Best suited | CPU-bounded tasks | I/O-bound tasks |
| Complexity | Simpler | More complex |
| Control over execution | less granular | more granular |
concurrent.futures#
- Uses threads or processes to execute tasks concurrently.
- Better suited for CPU-bound tasks by leveraging multiple cores.
- Simpler to use than
asynciofor basic concurrent operations.
asyncio#
- Uses an event-loop to manage asynchronous tasks.
- Execellent for I/O-bound tasks like network requests, file operations, etc.
- Offer fine-grained control over task scheduling and execution.
- Requires a deeper understanding of asynchronous programming concepts.
Summary#
concurrent.futures is like having multiple workers to handle tasks independently.
If you have multiple CPU-intensive tasks that can benefits from parallel execution, use concurrent.futures.
- it uses time-slicing model by allocates slot of CPU time to all threads..
- with many blocking threads (for long period), it begins to degrade into polling.
- Time-slicing is managed by the OS, giving the programmer less control over thread scheduling.
asyncio is like having a single worker that can efficiently juggle multiple tasks without blocking.
If you have many I/O-bound tasks that need to be handled efficiently without blocking the main thread, use asyncio.
- it uses an event-loop, and is more akin to push-notification model.
- it works by waiting for it to announce it’s availability (not checking the threads).
- Event-loop which based on polling/interrupt as core mechanism, continuous checks (pools) for I/O events or task completion.
- This makes
asynciooffers more efficient for I/O-bound tasks, as it avoids unnecessary CPU usage when tasks are waiting for I/O.